How to use Terraform remote backends
Brendan Thompson • 28 January 2022 • 12 min read
What is a Backend#
The primary function of a backend is to store the state created by Terraform runs after provisioning our resources. This gives Terraform a single place to look up what the expectation of our resources is from the last time we applied; it also forms a part of how Terraform does reconciliation of the resources. To truly understand backends and their purpose, we must first understand the three forms or phases that our resources can be in:
Desired State — the state we wish for our resources to be in, this is represented by our Terraform code.
Existent State — the state our resources are according to where they are deployed; in the case of Azure, it would be the state of the resources in the cloud (visible via the Portal/API).
Observed State — the state that Terraform has observed or augmented the resources to be in at its last run; this representation is held inside state files within our backend.
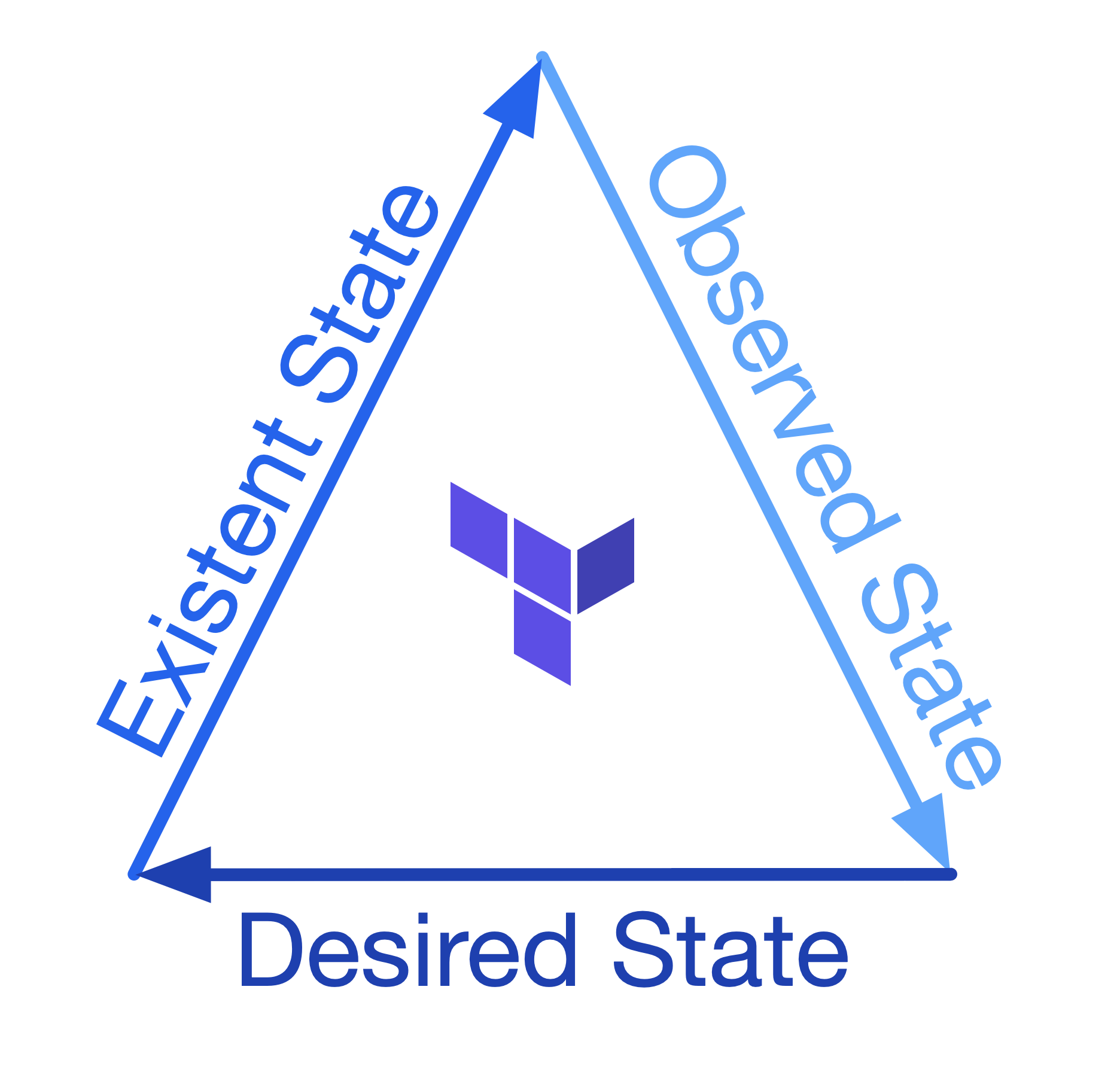
Terraform will use the three phases of our resource state to reconcile and ensure that the deployed resources are in the form we want them to be in, the desired state.
Backend Types#
At a very high level, there are two types of backends:
- Local — where the state file is stored on the local filesystem.
- Remote — where the state file is stored in some remote filesystem or database.
Under the Remote backend type, there are many subtypes. This allows for a lot of flexibility when storing our state.
Local#
Let's dive a little into the Local Backend. You usually wouldn't configure this backend as
I tend to use it when testing things locally or to begin my journey of writing Terraform for
something. However, this doesn't mean that you cannot configure this backend at all. The Local backend
allows you to set an optionally different workspace_dir and path for your state file. The path
option must be relative to either your root module or the defined workspace_dir.
terraform {
backend "local" {
workspace_dir = "/Users/brendanthompson/Development/terraform-state"
path = "awesome-project/development.tfstate"
}
}
Remote#
There are many remote backends to choose from; I will not go through all of them in this post, just the most common ones or that I see as most useful. You can, however, see an exhaustive list here.
Remote backends fall into two categories; the first is just a store for Terraform state like the Cloud Specific Backends, the others like Terraform Cloud and Scalr not only stores Terraform state but also acts as an executor or orchestrator of your Terraform code. The latter reduces the requirement on engineers to build out custom orchestration solutions and means that you can spend more time engineering!
Terraform Cloud#
If you're looking to be cloud-agnostic, then I would recommend using this Terraform Cloud option or the below Scalr option as they will both allow you to store state without caring about the underlying infrastructure or storage mechanism.
Cloud offers some of the best functionality out of the box as it is the direction HashiCorp seem to be driving their products. This push to Cloud could be seen as a positive or negative and is undoubtedly something worth digging into more in another post.
To configure our Terraform code to use the Cloud state, we must do this a little differently to all
other ways; instead of having a backend {} block, we rather will have a cloud {} block.
This block also allows us to configure other things about cloud configuration.
The code below shows how we can configure our code to utilize the department-of-mysteries workspace
in the Terraform Cloud organization ministry-of-magic.
terraform {
cloud {
organization = "ministry-of-magic"
workspaces {
name = "department-of-mysteries"
}
}
}
There is another argument we can use within our workspaces {} block instead of name, and that is
the tags argument. Using this allows us to execute changes on any workspaces containing these tags
with a single set of Terraform code.
terraform {
cloud {
organization = "ministry-of-magic"
workspaces {
tags = ["department:mysteries", "compute:kubernetes"]
}
}
}
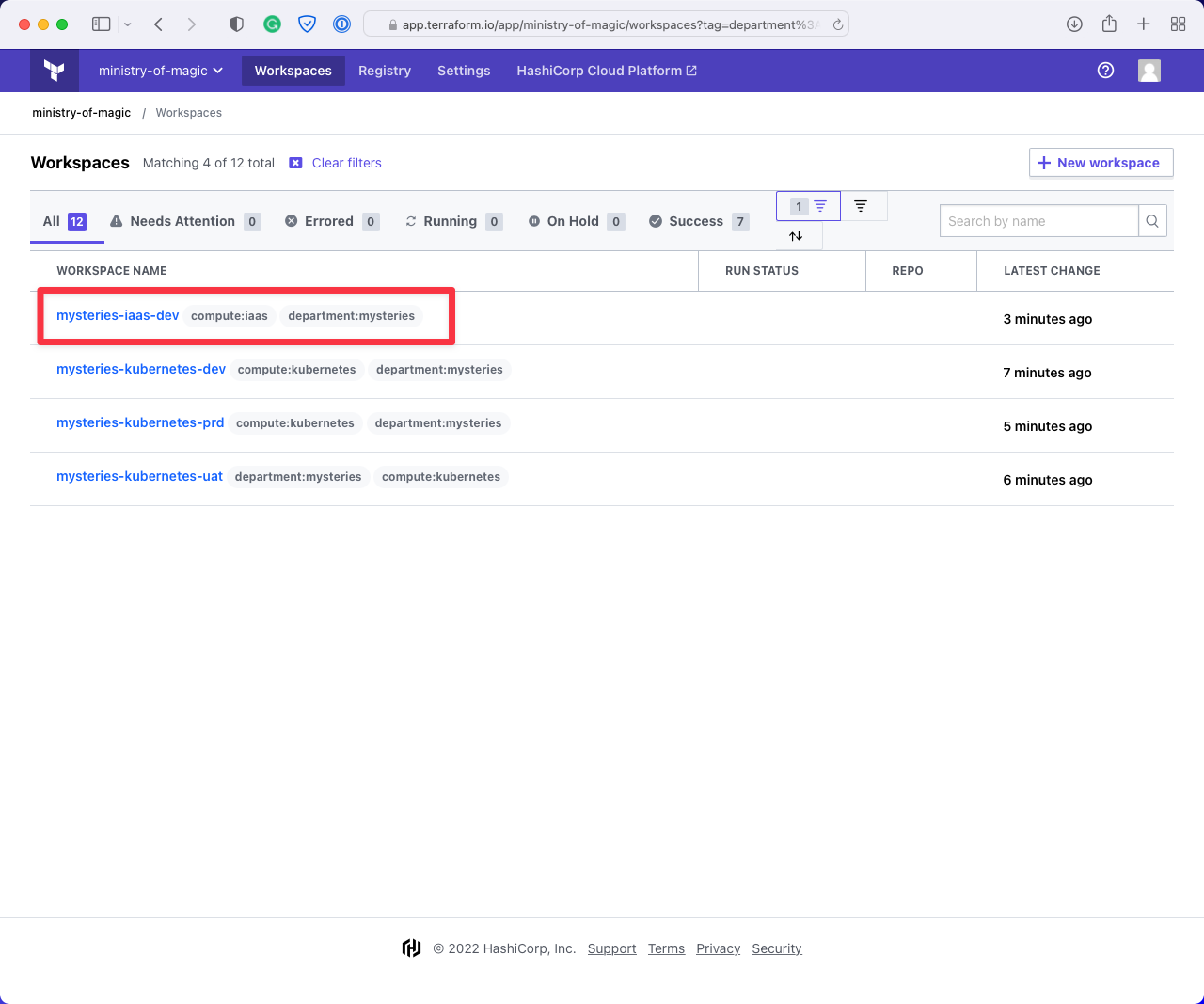
To help articulate what is happening here a little better, below are some screenshots from this workspace.
This first screenshot shows when we filter on department:mysteries in the Cloud console that, we get
workspaces for three environments for compute:kubernetes and one for compute:iaas, as our hypothetical
code is going to be dealing with Kubernetes infrastructure it could do some damage to that compute:iaas
workspace.
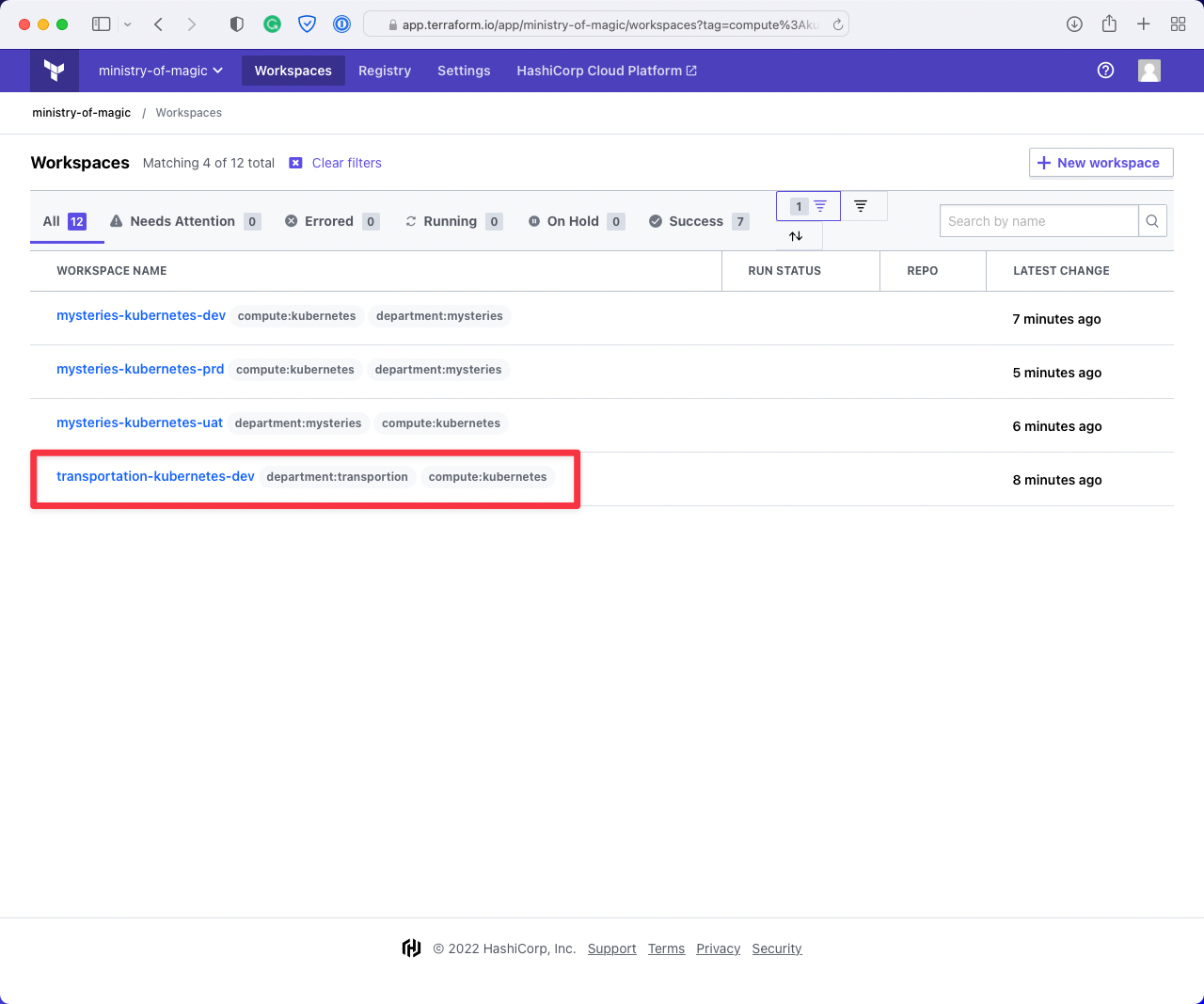
This next image shows the workspaces returned when filtering on compute:kubernetes. As you can see
it is also returning us a workspace for the department:transportation, we don't want to be effecting
workspaces that aren't under our remit!
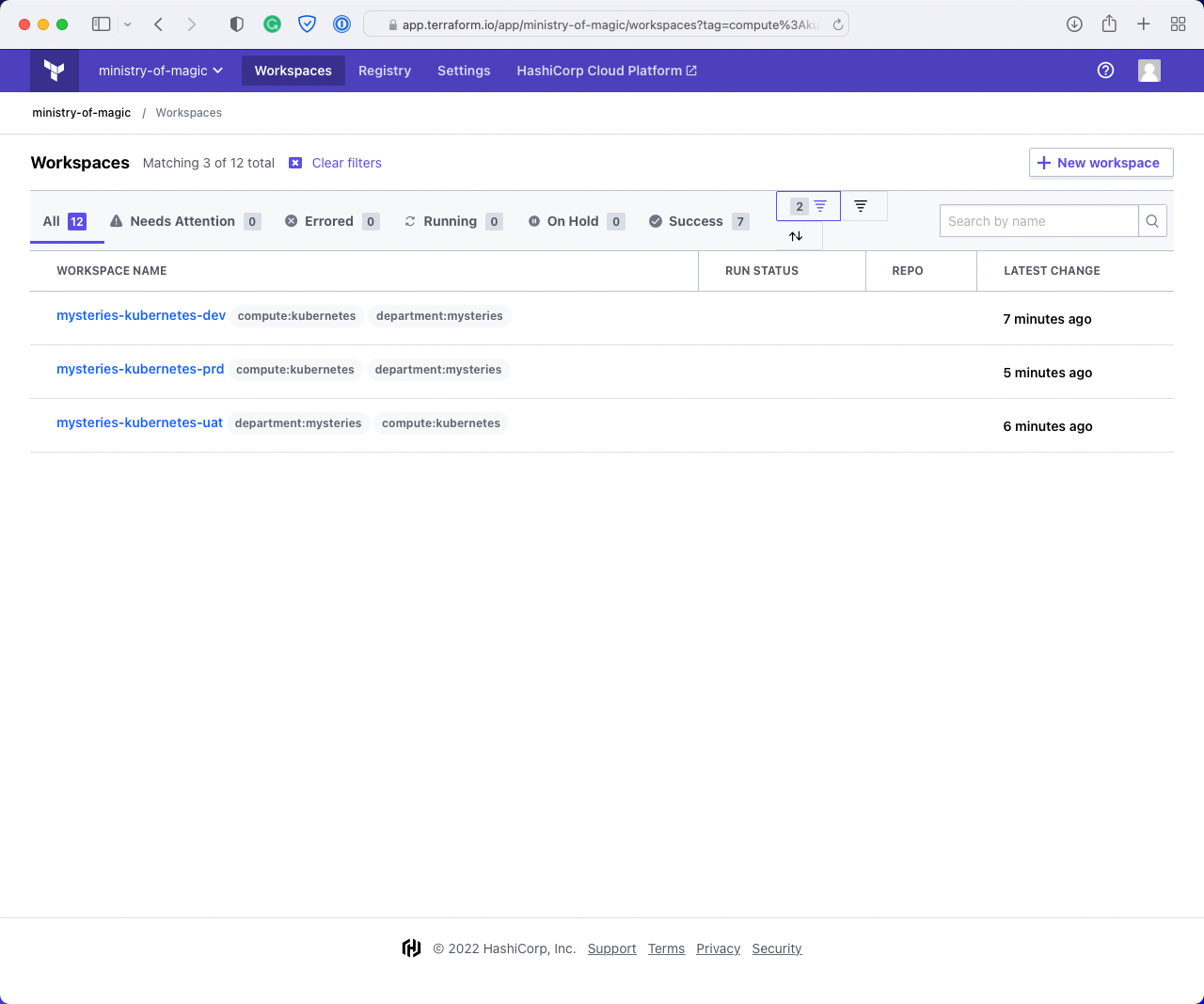
Finally, we have applied both department:mysteries and compute:kubernetes which gives us exactly
what we want; all the Kubernetes workspaces for the Department of Mysteries.
Using the Terraform CLI from our codebase, we can query to see what workspaces we can execute this code on, the below screenshot shows what our example code would return is.
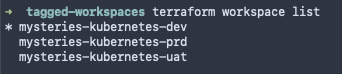
We can check which workspace is currently selected with terraform workspace show

And finally, we can select a different workspace using terraform workspace select <Workspace_Name>
that will allow our code to execute in that new workspace when triggered via the CLI.

This should show how powerful using the tags argument is for this backend type!
Scalr#
As Scalr adheres to the interface for backends, it means that it's straightforward for us to
configure our code to use it. We use the remote backend type; with this, we can pass in
very similar arguments that we did for the Terraform Cloud backend type.
You can use this same method with a TFC workspace, although it is no longer recommended.
In this instance, we are going to deploy the ministry-of-magic organization into our Non-production
environment, in the mysteries-kubernetes-dev workspace. The hostname argument refers to our
instance of Scalr, the organization refers to the environment within our instance, and a
workspace is just a workspace!
terraform {
backend "remote" {
hostname = "ministry-of-magic.scalr.io"
organization = "env-tqaqjimtnmmgiv0"
workspaces {
name = "mysteries-kubernetes-dev"
}
}
}
At this stage, Scalr does not have workspace tags, nor does the remote backend type support
them. However, there is another option in the prefix argument; this allows you to use a prefix to
select which workspaces the code will deploy to. An example of this is below:
terraform {
backend "remote" {
hostname = "ministry-of-magic.scalr.io"
organization = "env-tqaqjimtnmmgiv0"
workspaces {
prefix = "mysteries-kubernetes-"
}
}
}
In the below screenshot, I have highlighted the workspaces that the code would apply to.
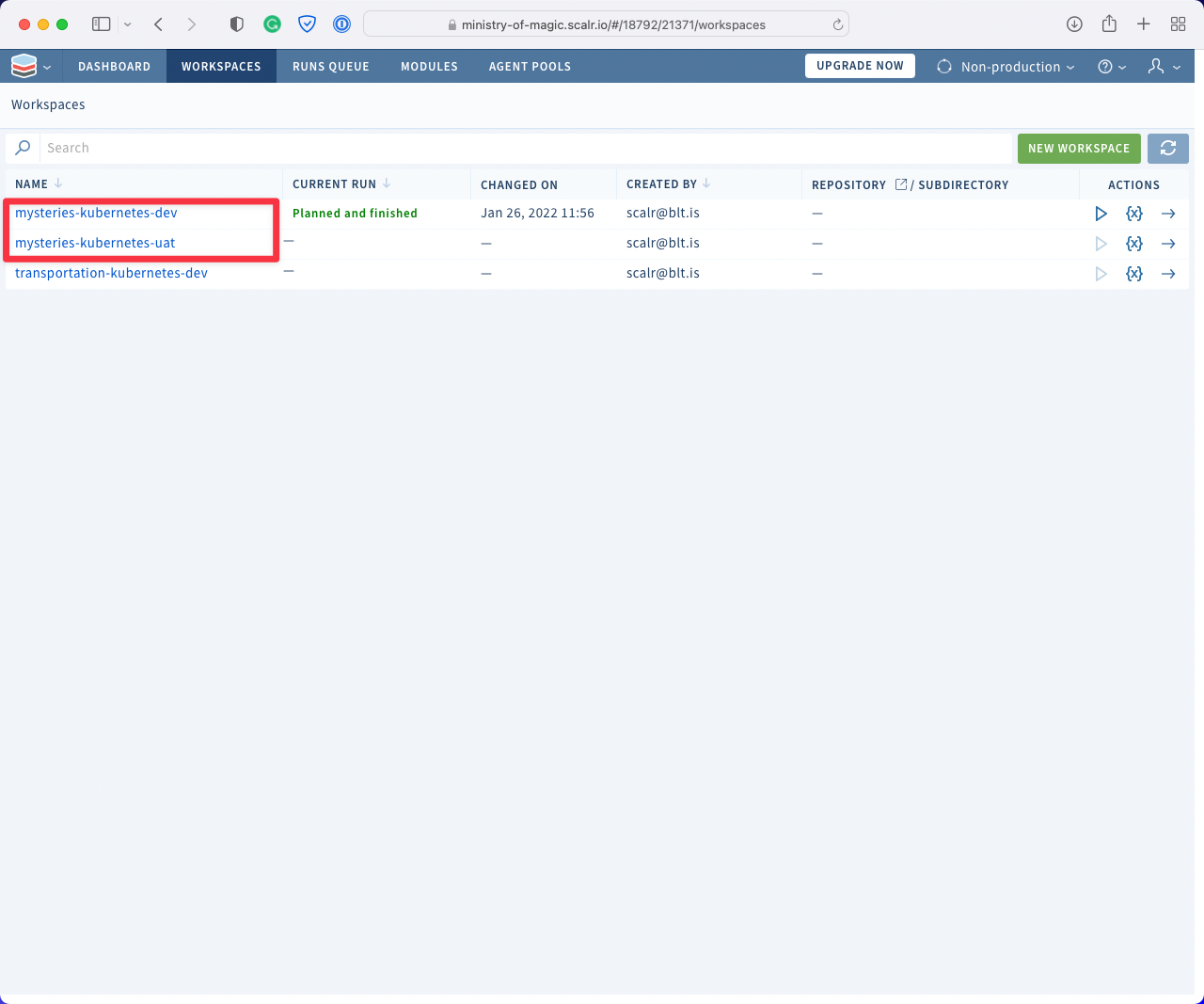
The same as with Terraform Cloud we need to use the terraform workspace
subcommands to switch between our different environments.
With terraform workspace show we get:

With terraform workspace list we can see the two workspaces, as expected:

And finally we can select our uat workspace with terraform workspace select:

Cloud Specific Backends#
Now we delve into the realm of the Cloud Specific Backends, these all rely on a particular clouds storage service. They also somewhat lock you into that cloud vendor given you're using one of its services to store your state. Something important to think about when using Cloud Specific Backends is the fact that you are now responsible for ensuring there are backups of your state files incase of corruption or requirement to restore, with the other remote instances Terraform and Scalr both take care of this for you.
Azure: azurerm#
With the azurerm backend we need to think about a few more things than in the previous scenarios
let's go through an example and break it down.
terraform {
backend "azurerm" {
resource_group_name = "rg-aus-prd-mom-state"
storage_account_name = "saausprdmomstate"
container_name = "dev"
key = "mysteries-kubernetes.terraform.tfstate"
}
}
As can be seen above we must configured several arguments in order for Terraform to know where to put our state file as well as what to call it, lets go through them:
resource_group_name— the Azure resource group where the storage account is provisioned.storage_account_name— the storage account where our storage container exists.container_name— the name of the storage container where our state files will live. As a rule of thumb I will create a container for either each environment I am deploying to or each area.key— the file name of the state file itself. Depending on what I have done with thecontainer_nameI will prefix thekeywith the area or the environment.
When I talk about area above this could refer to a few things which I have listed below, it could even be a combination of a few or all of these:
- Region — the region with Azure where the resources are deployed.
- Project — the abbreviation of a project to which the resources belong to.
- Resource Domain — the domain of the resources, e.g. networking, identity or compute.
- Consumption Domain — the domain consuming these resources, think a department in a business.
With this particular backend type it is also possible to configure authentication in several ways, for this I would recommend assessing what your organisation currently uses for Azure authentication and then refer to the backend docs to better understand how to implement that authentication with the backend.
GCP: gcs#
Google Cloud Storage or GCS is the Cloud Specific Backed for Google Cloud Platform (GCP) it shares some
similarities to the Azure variant. Configuring gcs is a little simpler than azurerm due to the
reduction in argument requirements. Google Cloud unlike Azure scopes your client
automatically to a Google Cloud Project this is the smallest level of grouping available on
GCP, this means we do not need to include any information about that in our backend config.
Below I have used the same example as I have with azurerm so you can easily see how things change:
terraform {
backend "gcs" {
bucket = "gcs-syd-prd-mom-state"
prefix = "dev/mysteries-kubernetes"
}
}
By default Terraform will create a state file called default.tfstate in the bucket
dev/mysteries-kubernetes. Now, if you were to use terraform workspace it would create a file
named after whatever is shown in terraform workspace show.
AWS: s3#
Finally for our Cloud Specific Backends we have our Amazon Web Services (AWS) option of an s3 bucket! The same as with Azure and GCP we are storing our state in a storage container, s3 requires close to the same parameters as GCS as you will see below:
terraform {
backend "s3" {
bucket = "s3sydprdmomstate"
key = "dev/mysteries-kubernetes.tfstate"
region = "ap-southeast-2"
}
}
We have had to define three things here:
bucket— the name of the s3 bucket where our state will reside.key— the pathway within our bucket where the state will be placed, this should follow a logical structure and the final segment will become the name of the state file.region— the AWS region where thebucketexists.
terraform workspace with an s3 backend the structure within the bucket will change slightly. If we said that we had done terraform workspace select uat and our key was set to mysteries-kubernetes.tfstate we would end up with a bucket pathway/key that looked like:s3sydprdmomstate/env:/uat/mysteries-kubernetes.tfstate
Closing out#
This post has been a run-through of using some of the most common backend types for Terraform. We have also gone through the most basic configuration for each backend which will be enough to get you started on any of them! There are undoubtedly many ways to configure and use each of these; however, I hope this post has opened your eyes to what is available and how best to get started.
If you're interested in how you dynamically setup backends to make your code even more efficient then check out my post How to set Terraform backend configuration dynamically